Motion Under Occlusion, pt.4: GCC-PHAT and the Fejér Kernel
- 19 minsAs promised, this post covers the cross-correlation phase transform (PHAT), a generalization, and connections to our algorithm — all in a 1D formulation.
Problem: 1D formulation
Recall that we are working with a 2D image modality. To think of the 1D formulation of the problem- imagine “slicing” a 3D motion video of dimensions (T, H, W) with respect to either horizontal/vertical axis, and looking at the intensity changes within some chosen axial ‘strip’ across the video, resulting in a 2D motion sequence.
In the case of our white-square object, any horizontal strip $(I_{0}[i]..I_{N-1}[i])$ within the range $i \in [\frac{H}{4}, \frac{3H}{4}]$ could provide suitable information, and similarly for a vertical strip $j \in [\frac{W}{4}, \frac{3W}{4}]$ (why are the two equivalent?), where ideally we would choice a strip somewhere in the middle. Note that each such strip corresponds to a shifted rectangular pulse per video-frame.
We can use the following code to provide an example of what integrated images corresponding to different shifts would look like, where we use as our initial signal a rectangular pulse of width $|rect|=32$, and a motion sequence of the same length $T = |rect|$.
import torch
import matplotlib.pyplot as plt
def integrate_mean_by_roll(x: torch.Tensor, T: int, tau: int) -> torch.Tensor:
"""
Build T frames by successively rolling x by j*tau (j=0..N-1),
then return the mean. tau is integer; torch.roll is circular.
"""
L = x.numel()
acc = torch.zeros_like(x)
for j in range(T):
acc += torch.roll(x, shifts=(j * tau) % L, dims=0)
return acc / N
# Signal: rectangular pulse (Heaviside window)
M = 256
width = M//8 + 1
x = torch.zeros(M)
lower = M//2 - width//2
upper = M//2 + width//2
bounds = slice(lower, upper)
x[bounds] = 1.0
T = width
# ---- Compute integrated signals for each tau ----
taus = [1, 2, 3]
integrated = {tau: integrate_mean_by_roll(x, T, tau) for tau in taus}
# ---- Plot ----
plt.figure(figsize=(10, 5))
idx = torch.arange(M) - M//2
plot_bounds = slice(lower - width//2, len(idx))
for tau in taus:
plt.plot(idx[plot_bounds], integrated[tau].numpy()[plot_bounds],
label=fr"$\tau = {tau}$")
# (Optional) show original signal for reference (light dashed)
plt.plot(idx[plot_bounds], x.numpy()[plot_bounds], '--', alpha=0.4, label="original x")
plt.xlabel("Index")
plt.ylabel("Integrated mean value")
plt.title(f"Mean of T={T} shifted signals for different shift values τ")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig("integrated_sigs.png")
plt.show()
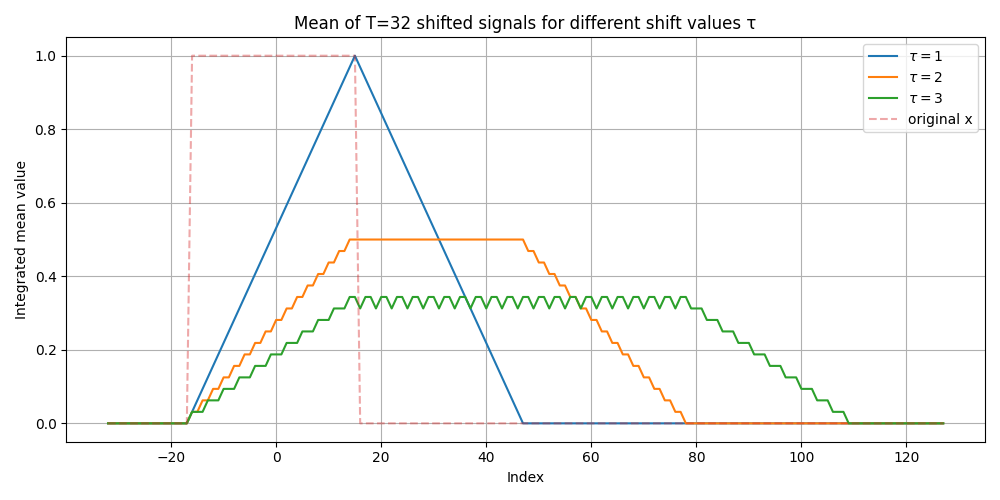
Note that the integrated image begins triangular for $\tau=1$, gradually becoming trapezoidal and wider for successive integer shift values $\tau \in [2, N]$, until we can imagine it ‘collapsing’ to a line for arbitrarily large N.
Integration as a cross-correlation kernel
Recall from the previous blogpost that we briefly mentioned that $\operatorname{tri}(t) = \operatorname{rect}(t) \circledast \operatorname{rect}(t)$
Is this a coincidence? I think not! To better understand this, let’s express the integration operation in terms of a linear operation of the image with some kernel h. For a given shift $\tau$ the integration operation is equivalent to
\(\begin{aligned} \overline{I}[x] &= \frac{1}{T}\sum_{t=0}^{N-1} I[x - t\tau] = \frac{1}{T}\sum_{t=0}^{N-1} I[x] \cdot \delta [x - t\tau] \\[4pt] &\overset{\text{linearity}}\propto I[x] \star h_{\tau} \end{aligned}\)
Where $\star$ is the cross-correlation operation, and $h_{\tau}(x)= \sum_{t=0}^{N-1} \delta [x - t\tau]$ (note: this kernel is known as a Dirac comb).
Now for the case $\tau=1$ we have
\(h_{\tau =1}(x) = \sum_{t=0}^{N-1} \delta [x - t] = \begin{cases} 1, & 0 \le t \le N-1, \\ 0, & \text{otherwise.} \end{cases}\)
which is another rectangular pulse! Finally then we get
\(\overline{I}_{\tau =1}[x]\propto I[x] \star h_{\tau =1}(x) = rect[x] \star rect[x] = tri[x]\)
Now that we understand how to think about 1D integration, let’s move on to more interesting things, mainly the phase-correlation algorithm, and surprising connection to our optimization objective.
Cross-correlation phase-transform (PHAT)
The phase-correlation algorithm is a well-known tool in signal processing for computing translation between two images, where it is based on the very simple notion of a phase transform.
Recall the duality
\(x[n-n_0]\overset{\text{FT}}{\leftrightarrow}e^{-j\omega n_0}\cdot X(e^{j\omega})\)
known as the Fourier shift-theorem.
Now if we have two signals $x_1, x_2$ where we know that $x_2[n] = x_1[n-n_0]$, we can solve for $n_0$ using what’s known as a phase transformation, which is an operation which extracts only the phase component of a Fourier-domain signal representation, equivalent to $e^{-j\omega n_0}$ in this case.
Let’s show this in action: using the Fourier shift theorem, we have
\(\begin{aligned} X_2(e^{j\omega}) &= e^{-j\omega n_0}\cdot X(e^{j\omega}) \\[4pt] \frac{X_2 \cdot \overline{X_1}}{|X_2 \cdot \overline{X_1}|} &\overset{\text{PHAT}}= \frac{ e^{-j\omega n_0}X_1 \cdot \overline{X_1}}{|e^{-j\omega n_0}X_1 \cdot \overline{X_1}|} \\[4pt] &\overset{\text{unity}}= \frac{ e^{-j\omega n_0}|X_1|^2}{|X_1|^2} = e^{-j\omega n_0} \end{aligned}\)
where $\overline{X_1}$ is the complex conjugate of $X_1$. Now the final step to compute $n_0$ is to take the inverse Fourier transform
\(x_{PHAT} = \mathcal{F}^{-1}(e^{-j\omega n_0}) = \delta [n - n_0]\)
Which results in a shifted Dirac delta (unit impulse) function. We note that the peak must appear at index $n_0$, meaning that we can solve for it by
\(n_0 = \mathop{\mathrm{arg\,max}}\limits_{n} \left( \operatorname{Re}(x_{PHAT}[n]) \right)\)
where we only care about the real component of the resulting time-domain phase-transformed signal, meaning the component corresponding to the shifted Dirac delta.
Note that traditionally the $\mathop{\mathrm{arg\,max}}\limits_{n}$ operator is non-differentiable, in the sense that we scan $x_{PHAT}$ for an index yielding a maximum value.
What would be necessary then to make an equivalent differentiable implementation, yielding the same index? Could we formulate the algorithm as an optimization objective and solve for the correct shift via auto-differentiation?
Differentiable PHAT (‘naive’)
To get a better understanding of what’s happening in the final step of the algorithm, let’s explicitly write out the real part of $x_{PHAT}$:
\(\begin{aligned} \Re\{x_{\text{PHAT}}[n]\} &= \Re\!\left\{ \frac{1}{N}\sum_{k=0}^{N-1} e^{j\omega_k (n - n_0)} \right\} \\[4pt] &\overset{\text{trig.}}= \frac{1}{N}\sum_{k=0}^{N-1}\cos{(\omega_k \Delta n)} \end{aligned}\)
Where $\Delta n = n - n_0$.
Is this a decent optimization objective? On the one hand plugging in $n=n_0$ we obtain a global maxima, via
\(\frac{1}{N}\sum_{k=0}^{N-1}\cos{(\omega_k 0)} = \frac{1}{N}\sum_{k=0}^{N-1}1 \geq \sum_{k=0}^{N-1}\cos{(\omega_k \Delta n)}, n \neq n_0\)
On the other hand, it is enough to confirm that
\(\sum_{k=0}^{N-1}{e^{j\omega_k (n - n_0)}} = e^{j\omega_{k_0}} \sum_{k'=-\frac{N-1}{2}}^{\frac{N-1}{2}}{e^{j\omega_{k'} (n - n_0)}} = e^{j\omega_{k_0}} * D_N(\Delta n)\)
Where we ‘centered’ our signal to obtain the Dirichlet kernel of order N. This can easily be factorized to
\(D_{N}(x)=\sum _{k'=-k_0}^{k_0}e^{jk'x}=\frac {\sin \left(\frac{Nx}{2}\right)}{\sin(\frac{x}{2})}\)
Where the right-hand form becomes highly oscillatory as N grows, which is a big “no-no” for successful optimization.
Given what we’ve learned about the importance of bilinear interpolation as an effective low-pass filter in our original optimization objective, can we think of some ‘equivalent’ (dual) operation in the given case?
The Fejér kernel
The Fejér kernel is defined by
\(F_{N}(x)=\frac {1}{N}\sum _{k=0}^{N-1}{D_{k}(x)}\)
Meaning that the Nth Fejér kernel is built by integrating and smoothing the first N Dirichlet kernels. We can think of this operation as a ‘summation over summations’ (recall the definition of a Dirichlet kernel as a finite geometric series). Plugging in the explicit Dirichlet kernel formula (and skipping some math on the way) gives us the following explicit formula for a kernel of order N
\(F_{N}(x)={\frac {1}{N}}\left({\frac {\sin({\frac {Nx}{2}})}{\sin({\frac {x}{2}})}}\right)^{2} \overset{\text{FT}}{\longleftrightarrow} \left(1-{\frac {|k|}{N}}_{|k|< N-1}\right)\)
meaning that the frequency representation of the Fejér kernel results in triangular weights, which we previously saw in the time-domain as a triangular kernel! Duality once again.
We understand then that the kernel is positive, and its corresponding frequency response is a steeper low-pass filter (less high-frequency components) than that of the Dirichlet kernel. This makes sense given our previously-gained knowledge that integration corresponds to low-pass filtering!
PHAT optimization objective (code)
Let’s show with some code that the Fejér kernel objective has better convergence properties than that of the Dirichlet kernel. Note that we use the frequency-domain representation of the kernel in our implementation.
import math
import torch
import matplotlib.pyplot as plt
def fejer_weights(C: torch.Tensor):
"""
Fejér-type weights for a 1D spectrum C_alpha of shape (K,).
Highest weight at DC (index 0), decaying linearly to ~0 at the highest index.
"""
K = C.shape[0]
device = C.device
k = torch.arange(K, device=device)
return 1.0 - k / (K - 1 + 1e-8)
def phat_objective(x1: torch.Tensor,
x2: torch.Tensor,
tau: torch.Tensor,
exclude_dc: bool = True,
method: str = "phat",
) -> torch.Tensor:
"""
f(tau) = Re{ mean_k [ C_normed[k] * exp(-i*ω_k*tau) ] } (method="phat")
or a Fejér-weighted surrogate (method="fejer").
We maximize f(tau) over τ.
"""
assert x1.shape == x2.shape and x1.ndim == 1
M = x1.shape[0]
k = torch.arange(M, dtype=x1.dtype, device=x1.device)
omega = 2 * math.pi * k / M
X1 = torch.fft.fft(x1)
X2 = torch.fft.fft(x2)
CPS = X1 * torch.conj(X2)
mag = torch.clamp(torch.abs(CPS), min=1e-12)
C_normed = CPS / mag
if exclude_dc:
C_normed = C_normed[1:]
omega = omega[1:]
C_shifted = C_normed * torch.exp(-1j * omega * tau)
if method == "fejer":
weights = fejer_weights(C_shifted)
C_shifted *= weights
dirichlet = torch.real(C_shifted)
return dirichlet.mean()
def plot_kernel_comparison(ax, taus_grid, x1, x2):
"""Plot Dirichlet vs Fejér kernel comparison."""
dirichlet_vals = torch.tensor([float(phat_objective(x1, x2, t, method="dirichlet").detach())
for t in taus_grid])
ax.plot(taus_grid.numpy(), dirichlet_vals.numpy(), label='Dirichlet Kernel', linewidth=3)
fejer_vals = torch.tensor([float(phat_objective(x1, x2, t, method="fejer").detach())
for t in taus_grid])
ax.plot(taus_grid.numpy(), fejer_vals.numpy(), label='Fejér Kernel', linewidth=3)
ax.axvline(0, linestyle="--", color='red', label="True Shift τ*", alpha=0.8, linewidth=2)
ax.set_xlabel("Time Shift τ (samples)", fontsize=12)
ax.set_ylabel("Objective Function f(τ)", fontsize=12)
ax.set_title("Objective comparison", fontsize=14, fontweight='bold')
ax.grid(True, alpha=0.3)
ax.legend(fontsize=11)
x_shifted = x
plt.figure(figsize=(14, 8))
ax = plt.gca()
taus_grid = torch.linspace(-6.0, 6.0, 201, dtype=torch.float64)
plot_kernel_comparison(ax, taus_grid, x1, x2)
plt.tight_layout()
plt.show()
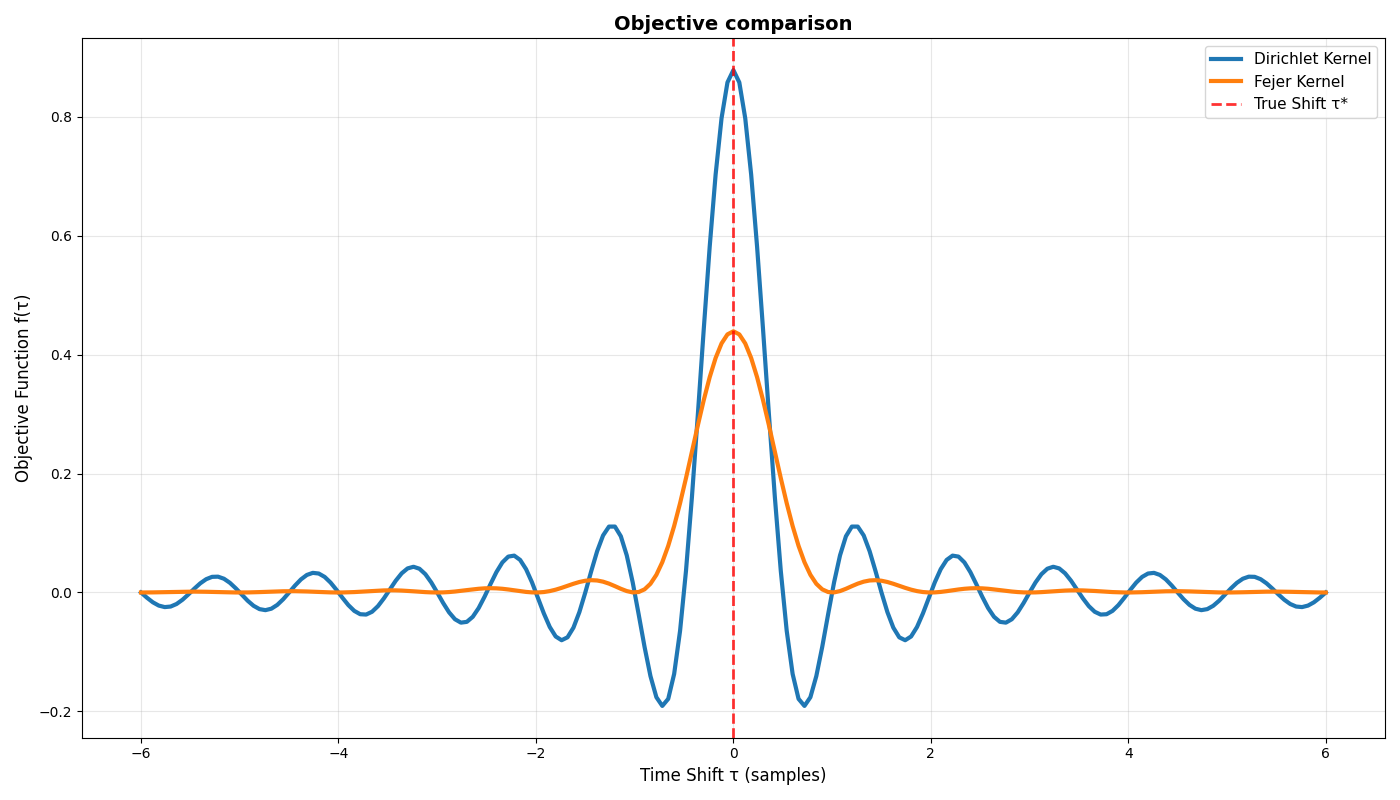
While the Fejér kernel improves on the Dirichlet, it is not a sufficient optimization objective in itself (what happens if we generate an initial shift which is arbitrarily far from the ground-truth shift?). We can assume then that phase-information in itself is most probably insufficient for establishing a useful optimization objective.
Given this assumption, how can we further improve our PHAT-based optimization objective?
Generalized Cross-Correlation (GCC)
The standard Generalized Cross-Correlation (GCC) function is defined in the frequency domain as:
\(R_{GCC}(\tau) = \int_{-\infty}^{\infty} \Psi(f) G_{xy}(f) e^{j2\pi f\tau} df\)
where:
- $ G_{xy}(f) $ is the cross-power spectrum
- $ \Psi(f) $ is the spectral-weighting function
And the rest is simply the inverse Fourier Transform of the spectrally-weighted cross-power spectrum. By applying Fejer weights in the frequency domain, we already have an example via $\Psi(f) = 1-{\frac {|k|}{N}}_{|k|< N-1}$, where we’ve seen that this operation is generally useful for optimization. Let’s now approach this spectral weighting function from a different angle!
To obtain our original PHAT formulation we can set “normalized” spectral weighting via $ \Psi(f) = \frac{1}{|G_{xy}(f)|}$. Now can we “tweak” this in a way which gives us more flexibility? The following idea gives us a family of such filters:
\(\Psi(f) = \frac{1}{\|G_{xy}(f)\|^\alpha}, \quad \alpha \in [0, 1]\).
For $ \alpha =1$ we get our original PHAT formulation, and for $ \alpha =0$ we have the original cross-power spectrum $G_{xy}$. We call this variant then GCC-PHAT, on account of its generating a whole “spectrum” between the phase-transformation and cross-power spectrum variants.
Let’s see the effect of varying this alpha on our optimization objective, slightly revising our previous code
def gcc_phat_objective(x1: torch.Tensor,
... # as previously
alpha: float = 1.0
) -> torch.Tensor:
"""
f(tau) = Re{ mean_k [ C_normed[k] * exp(-i*ω_k*tau) ] } (method="phat")
or a Fejér-weighted surrogate (method="fejer").
We maximize f(tau) over τ.
"""
# as previously
...
mag = torch.clamp(torch.abs(CPS), min=1e-12) ** alpha
... # as previously
return dirichlet.mean()
def plot_kernel_comparison(ax, taus_grid, x1, x2, alpha=1):
"""Plot Dirichlet vs Fejér kernel comparison."""
dirichlet_vals = torch.tensor([float(gcc_phat_objective(x1, x2, t, method="dirichlet", alpha=alpha).detach())
for t in taus_grid])
ax.plot(taus_grid.numpy(), dirichlet_vals.numpy(), label='Dirichlet Kernel', linewidth=3)
fejer_vals = torch.tensor([float(gcc_phat_objective(x1, x2, t, method="fejer", alpha=alpha).detach())
for t in taus_grid])
... # as previously
plt.figure(figsize=(14, 8))
ax = plt.gca()
taus_grid = torch.linspace(-6.0, 6.0, 201, dtype=torch.float64)
plot_kernel_comparison(ax, taus_grid, x1, x2, alpha=0.7)
plt.tight_layout()
plt.show()
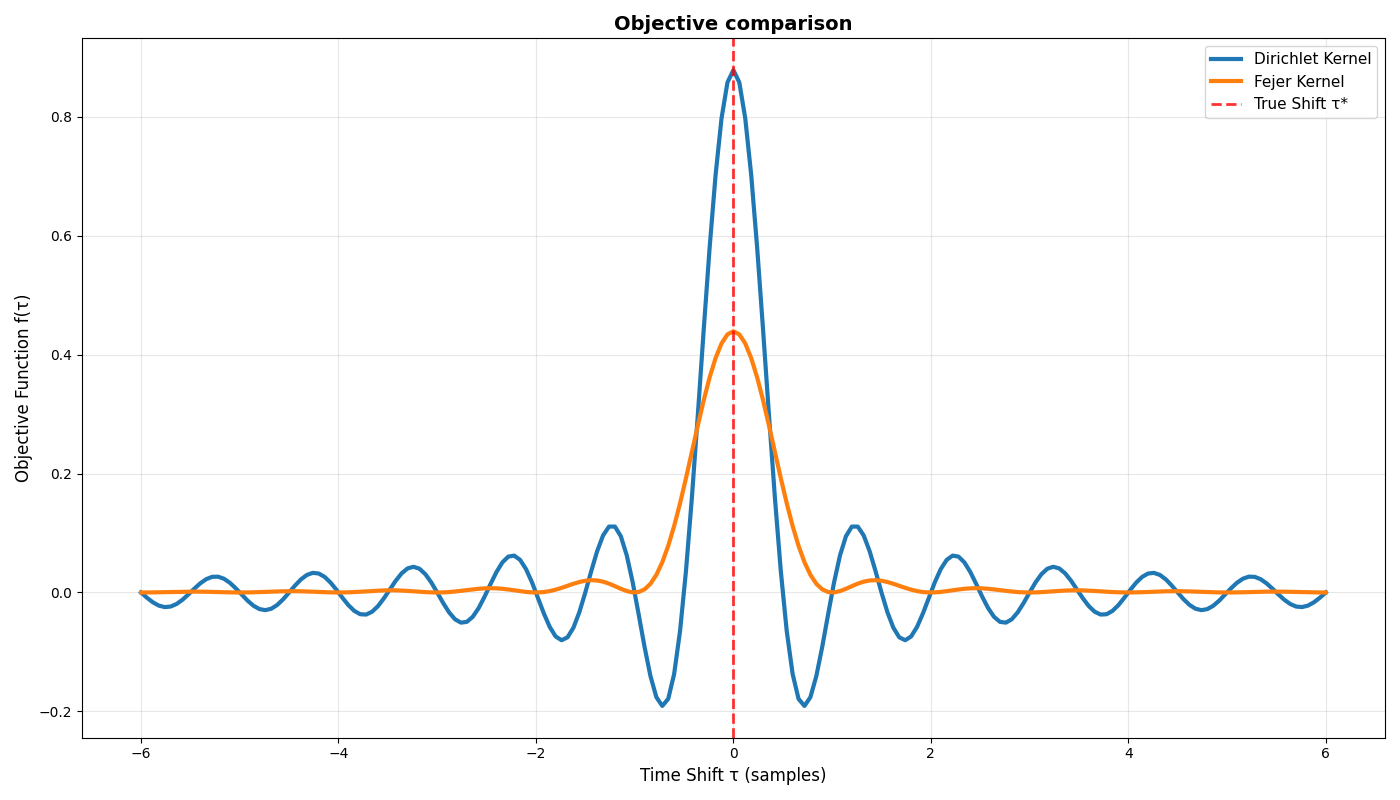
Now the Fejér-smoothed objective is starting to look like a decent optimization objective! Note that there are additional improvements which can be made to reduce some swells (high-frequency components) in the optimization landscape. For example- what would be the effect of integrating the Fejér kernels as we previously did to the Dirichlets (Hint- integration is a smoothing operation, and thus a low-pass filter)?
GCC-PHAT for video sequences
Our original variance objective corresponds to $\alpha=0$ — it uses only energy (magnitude) and ignores phase information entirely. The sections above showed that pure phase ($\alpha=1$) gives a Dirichlet-kernel objective that is too oscillatory to optimize reliably, but that Fejér-smoothed GCC-PHAT at an intermediate $\alpha$ can strike a useful balance between sharpness and smoothness. Can we bring this to bear on our optimization?
The key insight is that applying the moving average to even- and odd-indexed frame subsets separately produces two integrated images whose Fourier representations are related by a phase factor encoding the true shift $\tau^*$ — information that the variance objective (operating on magnitudes) was throwing away. GCC-PHAT on this pair lets us exploit that phase relationship directly.
We compute the two integrated images as follows:
\(\begin{aligned} I_{even} &= \frac{2}{N}\sum_{t=2m}^{N-1} e^{-j\omega t\phi} \cdot e^{-j\omega t\phi^*} \mathcal{F} \lbrace I_0 \rbrace \\[4pt] &= \mathcal{H_{\frac{N}{2}}}(\Delta \phi) \cdot \mathcal{F} \lbrace I_0 \rbrace \end{aligned}\)
where $\phi = \frac{\tau}{W}, \quad \Delta \phi = \frac{\tau - \tau^*}{W}$ and $\mathcal{H_{\frac{N}{2}}}$ is a moving-average filter of order $\frac{N}{2}$ (see previous blog-post) with frequency response parameterized by $\Delta\phi$.
$I_{odd}$ is constructed similarly over frames with odd time-steps, with the only exception
\(I_{odd} = \frac{2}{N}\sum_{t=2m+1}^{N-1} W^{\bf{t-1}}(I_t, \tau) = ...\)
Meaning that all odd-frames are translated back relatively to the first odd frame (why we do it this way will become clear soon).
Note that $\mathcal{H_{\frac{N}{2}}}(\Delta\phi)$ is maximized at $\Delta\phi = 0$, i.e.\ at the true motion $\tau = \tau^*$.
Now, note that
\(I_{even} = e^{-j\omega \phi^*} \cdot I_{odd}\)
Where $e^{-j\omega \phi^*}$ is a ground-truth phase shift.
From here on computing GCC-PHAT is quite straightforward:
\(\begin{aligned} \frac{I_{odd} \cdot \overline{I_{even}}}{|I_{odd} \cdot \overline{I_{even}}|^\alpha} &= \frac{e^{-j\omega \phi^*} I_{even} \cdot \overline{I_{even}}}{|e^{-j\omega \phi^*} I_{even} \cdot \overline{I_{even}}|^\alpha} \\[4pt] &= \frac{ e^{-j\omega \phi^*}|I_{even}|^2}{|I_{even}|^{2\alpha}} = |I_{even}|^{2(1-\alpha)}e^{-j\omega \phi^*} \end{aligned}\)
Let’s plug in different values for $\alpha$! Starting with $\alpha=0$ we get
\(|I_{even}|^2\cdot e^{-j\omega \phi^*} = \left|\mathcal{H_{\frac{N}{2}}}(\Delta \phi) \cdot \mathcal{F} \lbrace I_0 \rbrace\right|^2 \cdot e^{-j\omega \phi^*}\)
Optimizing over the magnitude of this signal,
\(\sum_{k \neq 0} \left|\mathcal{H_{\frac{N}{2}}}(\Delta \phi) \cdot \mathcal{F} \lbrace I_0 \rbrace\right|^2,\)
is equivalent to our original variance objective up to the order of the moving-average filter.
Connecting the two optimization objectives
We can “revert” our GCC-PHAT objective into the exact energy (variance) objective by computing the integrated image from integrated pairs by
\(\begin{aligned} \sum_{k \neq 0} \left|\frac{I_{even} + e^{-j\omega \phi} \cdot I_{odd}}{2}\right|^2 &= \sum_{k \neq 0} \left|\frac{1}{N} \sum_{t=0}^{N-1} W^t(I_t, \tau)\right|^2 \\[4pt] &= \sum_{k \neq 0} |\overline{I}|^2 = f_{obj}(\tau) \end{aligned}\)
We’ve essentially created a link between our two optimization objectives, where we can choose to branch out to either from some intermediate computation, depending on our need for flexibility, computational constraints, etc…
Conclusion
We now have “pure” energy (magnitude) and phase “flavors” of our GCC-PHAT objective, obtainable by choosing spectral-weighting factors $\alpha\in\lbrace {0,1} \rbrace$ respectively. The first maximizes coherent energy, while in the second the phase component is used to align a sharp correlation peak smoothed by the Fejér kernel (recall it is the ‘dual’ of the bilinear interpolation weights). The reversion shows both trace back to the same variance objective via the integrated even/odd pair.
The next post introduces an additive noise/occlusion model, analyzes the competition structure it creates in the objective, and uses that analysis to motivate a decoupled 4DoF pipeline.
Until then!